define inference --plain-english
Inference
TLDR:You hear this word everywhere once you're working with AI.
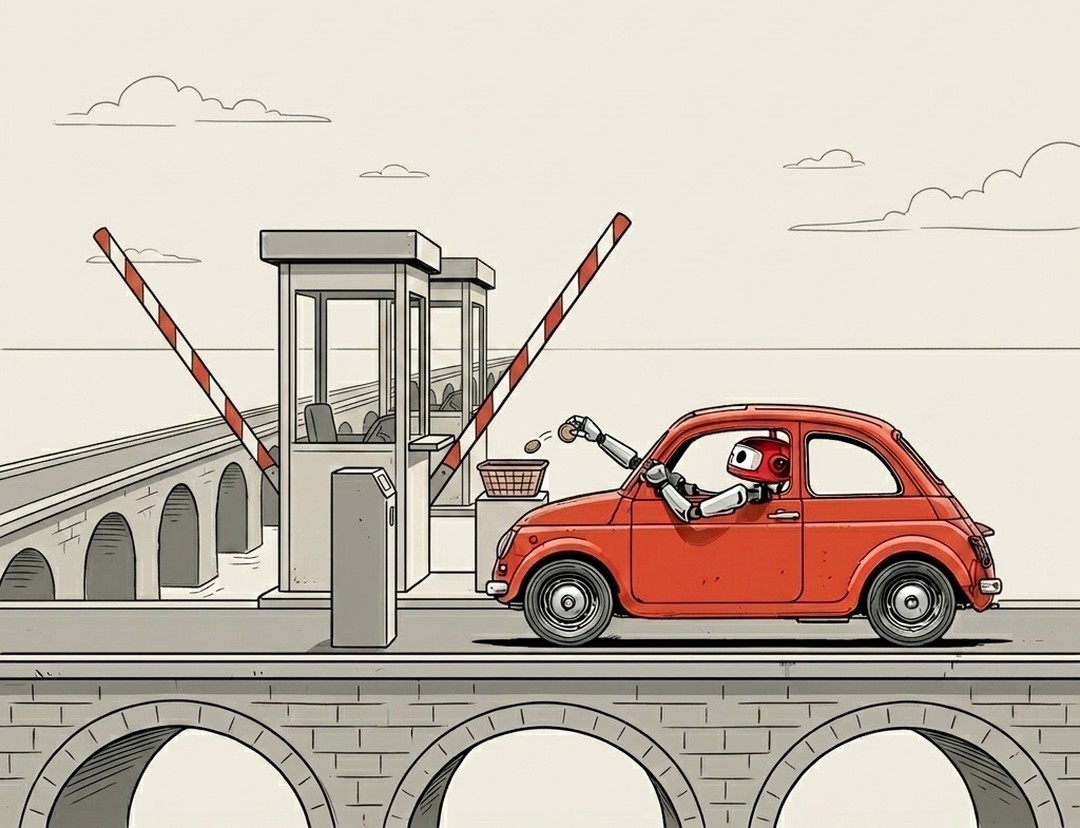
You hear this word everywhere once you're working with AI. Inference, inference, inference. I nodded along for a long time with no real idea what people meant. In plain English, this is what it is: every time you send a message to an AI and watch the answer come back, you're paying a toll to cross a bridge somebody else built. That toll is inference, and it's what your AI bill is mostly made of.
Building the model is building the bridge. It's enormous, slow, and paid for up front by whoever built it, long before you show up. A model gets fed a huge pile of text and tuned over weeks on rooms full of expensive chips until it's good. That's training. Inference is everything after: paying a small toll to cross that finished bridge one time. When you chat with an AI, the bridge is long built. Every message you send is one crossing.
This is the thing people get backwards. They assume the expensive part of AI is the bridge, the big smart model. For you, the builder, that part is already paid for. What you pay for, every day, is the toll: the cost of crossing one more time. Every API call, every step an agent takes, every reroll is another toll on the tab. And the bigger the load you haul across, the bigger the toll. Tokens are the little bricks the model reads and writes in. A long answer is just more bricks, a heavier truck across the bridge, so it costs more and takes longer. It's also why the words stream in one at a time. You're watching the truck cross.
So a few things that used to seem random suddenly make sense. "Loop this AI call a thousand times" is a sentence worth pausing on, because that's a thousand tolls. Prompt caching saves money because you pay to read a chunk once, then reuse it cheaply on later crossings. And a rate limit is just the bridge capping how many crossings you can make in a minute.
One last thing it clears up: when an AI feels slow, that's usually the crossing itself taking time, laying tokens down one by one, not the model "thinking harder." And when AI keeps getting cheaper and faster, which it does almost monthly, a lot of that is the toll dropping, not a brand-new bridge. The bridge stays expensive and rare to build. The toll keeps getting cheaper, and the toll is the part you actually pay.
Building the model is building the bridge: huge, slow, paid once. Inference is the toll you pay to cross it, every single time you use AI.